mirror of
https://github.com/arch3rPro/1Panel-Appstore.git
synced 2026-06-11 09:19:38 +08:00
feat(open-notebook): 添加Open Notebook应用及相关配置
This commit is contained in:
@@ -681,6 +681,18 @@ AI驱动的开源代码知识库与文档协作平台,支持多模型、多数
|
|||||||
|
|
||||||
<kbd>0.4.1</kbd> • [官网链接](https://next-ai-drawio.jiang.jp/)
|
<kbd>0.4.1</kbd> • [官网链接](https://next-ai-drawio.jiang.jp/)
|
||||||
|
|
||||||
|
</td>
|
||||||
|
<td width="33%" align="center">
|
||||||
|
|
||||||
|
<a href="./apps/open-notebook/README.md">
|
||||||
|
<img src="./apps/open-notebook/logo.png" width="60" height="60" alt="Open-Notebook">
|
||||||
|
<br><b>Open Notebook</b>
|
||||||
|
</a>
|
||||||
|
|
||||||
|
📝 私有的、多模型的Google Notebook LM替代方案,支持多模态内容和AI播客生成
|
||||||
|
|
||||||
|
<kbd>1.2.4</kbd> • [官网链接](https://www.open-notebook.ai/)
|
||||||
|
|
||||||
</td>
|
</td>
|
||||||
</tr>
|
</tr>
|
||||||
</table>
|
</table>
|
||||||
|
|||||||
@@ -0,0 +1,26 @@
|
|||||||
|
additionalProperties:
|
||||||
|
formFields:
|
||||||
|
- default: "8502"
|
||||||
|
envKey: PANEL_APP_PORT_HTTP
|
||||||
|
required: true
|
||||||
|
type: number
|
||||||
|
labelEn: Port
|
||||||
|
labelZh: 端口
|
||||||
|
edit: true
|
||||||
|
rule: paramPort
|
||||||
|
- default: "5055"
|
||||||
|
envKey: PANEL_APP_PORT_API
|
||||||
|
required: true
|
||||||
|
type: number
|
||||||
|
labelEn: API Port
|
||||||
|
labelZh: API端口
|
||||||
|
edit: true
|
||||||
|
rule: paramPort
|
||||||
|
- default: "8000"
|
||||||
|
envKey: PANEL_APP_PORT_DB
|
||||||
|
required: true
|
||||||
|
type: number
|
||||||
|
labelEn: Database Port
|
||||||
|
labelZh: 数据库端口
|
||||||
|
edit: true
|
||||||
|
rule: paramPort
|
||||||
@@ -0,0 +1,38 @@
|
|||||||
|
services:
|
||||||
|
open_notebook:
|
||||||
|
image: lfnovo/open_notebook:1.2.4
|
||||||
|
ports:
|
||||||
|
- ${PANEL_APP_PORT_HTTP}:8502
|
||||||
|
- ${PANEL_APP_PORT_API}:5055
|
||||||
|
env_file:
|
||||||
|
- ./docker.env
|
||||||
|
depends_on:
|
||||||
|
- surrealdb
|
||||||
|
volumes:
|
||||||
|
- ./notebook_data:/app/data
|
||||||
|
restart: always
|
||||||
|
container_name: ${CONTAINER_NAME}
|
||||||
|
networks:
|
||||||
|
- 1panel-network
|
||||||
|
labels:
|
||||||
|
createdBy: Apps
|
||||||
|
surrealdb:
|
||||||
|
image: surrealdb/surrealdb:v2
|
||||||
|
volumes:
|
||||||
|
- ./surreal_data:/mydata
|
||||||
|
environment:
|
||||||
|
- SURREAL_EXPERIMENTAL_GRAPHQL=true
|
||||||
|
ports:
|
||||||
|
- ${PANEL_APP_PORT_DB}:8000
|
||||||
|
command: start --log info --user root --pass root rocksdb:/mydata/mydatabase.db
|
||||||
|
pull_policy: always
|
||||||
|
user: root
|
||||||
|
restart: always
|
||||||
|
container_name: ${CONTAINER_NAME}-surrealdb
|
||||||
|
networks:
|
||||||
|
- 1panel-network
|
||||||
|
labels:
|
||||||
|
createdBy: Apps
|
||||||
|
networks:
|
||||||
|
1panel-network:
|
||||||
|
external: true
|
||||||
@@ -0,0 +1,259 @@
|
|||||||
|
|
||||||
|
# API CONFIGURATION
|
||||||
|
# URL where the API can be accessed by the browser
|
||||||
|
# This setting allows the frontend to connect to the API at runtime (no rebuild needed!)
|
||||||
|
#
|
||||||
|
# IMPORTANT: Do NOT include /api at the end - it will be added automatically!
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Docker on localhost: http://localhost:5055 (default, works for most cases)
|
||||||
|
# - Docker on LAN/remote server: http://192.168.1.100:5055 or http://your-server-ip:5055
|
||||||
|
# - Behind reverse proxy with custom domain: https://your-domain.com
|
||||||
|
# - Behind reverse proxy with subdomain: https://api.your-domain.com
|
||||||
|
#
|
||||||
|
# Examples for reverse proxy users:
|
||||||
|
# - API_URL=https://notebook.example.com (frontend will call https://notebook.example.com/api/*)
|
||||||
|
# - API_URL=https://api.example.com (frontend will call https://api.example.com/api/*)
|
||||||
|
#
|
||||||
|
# Note: If not set, the system will auto-detect based on the incoming request.
|
||||||
|
# Only set this if you need to override the auto-detection (e.g., reverse proxy scenarios).
|
||||||
|
API_URL=http://localhost:5055
|
||||||
|
|
||||||
|
# INTERNAL API URL (Server-Side)
|
||||||
|
# URL where Next.js server-side should proxy API requests (via rewrites)
|
||||||
|
# This is DIFFERENT from API_URL which is used by the browser client
|
||||||
|
#
|
||||||
|
# INTERNAL_API_URL is used by Next.js rewrites to forward /api/* requests to the FastAPI backend
|
||||||
|
# API_URL is used by the browser to know where to make API calls
|
||||||
|
#
|
||||||
|
# Default: http://localhost:5055 (single-container deployment - both services on same host)
|
||||||
|
# Override for multi-container: INTERNAL_API_URL=http://api-service:5055
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Single container (default): Don't set - defaults to http://localhost:5055
|
||||||
|
# - Multi-container Docker Compose: INTERNAL_API_URL=http://api:5055 (use service name)
|
||||||
|
# - Kubernetes/advanced networking: INTERNAL_API_URL=http://api-service.namespace.svc.cluster.local:5055
|
||||||
|
#
|
||||||
|
# Why two variables?
|
||||||
|
# - API_URL: External/public URL that browsers use (can be https://your-domain.com)
|
||||||
|
# - INTERNAL_API_URL: Internal container networking URL (usually http://localhost:5055 or service name)
|
||||||
|
#
|
||||||
|
# INTERNAL_API_URL=http://localhost:5055
|
||||||
|
|
||||||
|
# API CLIENT TIMEOUT (in seconds)
|
||||||
|
# Controls how long the frontend/Streamlit UI waits for API responses
|
||||||
|
# Increase this if you're using slow AI providers or hardware (Ollama on CPU, remote LM Studio, etc.)
|
||||||
|
# Default: 300 seconds (5 minutes) - sufficient for most transformation/insight operations
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Fast cloud APIs (OpenAI, Anthropic): 300 seconds is more than enough
|
||||||
|
# - Local Ollama on GPU: 300 seconds should work fine
|
||||||
|
# - Local Ollama on CPU: Consider 600 seconds (10 minutes) or more
|
||||||
|
# - Remote LM Studio over slow network: Consider 900 seconds (15 minutes)
|
||||||
|
# - Very large documents: May need 900+ seconds
|
||||||
|
#
|
||||||
|
# API_CLIENT_TIMEOUT=300
|
||||||
|
|
||||||
|
# ESPERANTO LLM TIMEOUT (in seconds)
|
||||||
|
# Controls the timeout for AI model API calls at the Esperanto library level
|
||||||
|
# This is separate from API_CLIENT_TIMEOUT and applies to the actual LLM provider requests
|
||||||
|
# Only increase this if you're experiencing timeouts during model inference itself
|
||||||
|
# Default: 60 seconds (built into Esperanto)
|
||||||
|
#
|
||||||
|
# Important: This should generally be LOWER than API_CLIENT_TIMEOUT to allow proper error handling
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Fast cloud APIs (OpenAI, Anthropic, Groq): 60 seconds is sufficient
|
||||||
|
# - Local Ollama with small models: 120-180 seconds may help
|
||||||
|
# - Local Ollama with large models on CPU: 300+ seconds
|
||||||
|
# - Remote or self-hosted LLMs: 180-300 seconds depending on hardware
|
||||||
|
#
|
||||||
|
# Note: If transformations complete but you see timeout errors, increase API_CLIENT_TIMEOUT first.
|
||||||
|
# Only increase ESPERANTO_LLM_TIMEOUT if the model itself is timing out during inference.
|
||||||
|
#
|
||||||
|
# ESPERANTO_LLM_TIMEOUT=60
|
||||||
|
|
||||||
|
# SSL VERIFICATION CONFIGURATION
|
||||||
|
# Configure SSL certificate verification for local AI providers (Ollama, LM Studio, etc.)
|
||||||
|
# behind reverse proxies with self-signed certificates
|
||||||
|
#
|
||||||
|
# Option 1: Custom CA Bundle (recommended for self-signed certs)
|
||||||
|
# Point to your CA certificate file to verify SSL while using custom certificates
|
||||||
|
# ESPERANTO_SSL_CA_BUNDLE=/path/to/your/ca-bundle.pem
|
||||||
|
#
|
||||||
|
# Option 2: Disable SSL Verification (development only)
|
||||||
|
# WARNING: Disabling SSL verification exposes you to man-in-the-middle attacks
|
||||||
|
# Only use in trusted development/testing environments
|
||||||
|
# ESPERANTO_SSL_VERIFY=false
|
||||||
|
|
||||||
|
# SECURITY
|
||||||
|
# Set this to protect your Open Notebook instance with a password (for public hosting)
|
||||||
|
# OPEN_NOTEBOOK_PASSWORD=
|
||||||
|
|
||||||
|
# OPENAI
|
||||||
|
# OPENAI_API_KEY=
|
||||||
|
|
||||||
|
|
||||||
|
# ANTHROPIC
|
||||||
|
# ANTHROPIC_API_KEY=
|
||||||
|
|
||||||
|
# GEMINI
|
||||||
|
# this is the best model for long context and podcast generation
|
||||||
|
# GOOGLE_API_KEY=
|
||||||
|
# GEMINI_API_BASE_URL= # Optional: Override default endpoint (for Vertex AI, proxies, etc.)
|
||||||
|
|
||||||
|
# VERTEXAI
|
||||||
|
# VERTEX_PROJECT=my-google-cloud-project-name
|
||||||
|
# GOOGLE_APPLICATION_CREDENTIALS=./google-credentials.json
|
||||||
|
# VERTEX_LOCATION=us-east5
|
||||||
|
|
||||||
|
# MISTRAL
|
||||||
|
# MISTRAL_API_KEY=
|
||||||
|
|
||||||
|
# DEEPSEEK
|
||||||
|
# DEEPSEEK_API_KEY=
|
||||||
|
|
||||||
|
# OLLAMA
|
||||||
|
# OLLAMA_API_BASE="http://10.20.30.20:11434"
|
||||||
|
|
||||||
|
# OPEN ROUTER
|
||||||
|
# OPENROUTER_BASE_URL="https://openrouter.ai/api/v1"
|
||||||
|
# OPENROUTER_API_KEY=
|
||||||
|
|
||||||
|
# GROQ
|
||||||
|
# GROQ_API_KEY=
|
||||||
|
|
||||||
|
# XAI
|
||||||
|
# XAI_API_KEY=
|
||||||
|
|
||||||
|
# ELEVENLABS
|
||||||
|
# Used only by the podcast feature
|
||||||
|
# ELEVENLABS_API_KEY=
|
||||||
|
|
||||||
|
# TTS BATCH SIZE
|
||||||
|
# Controls concurrent TTS requests for podcast generation (default: 5)
|
||||||
|
# Lower values reduce provider load but increase generation time
|
||||||
|
# Recommended: OpenAI=5, ElevenLabs=2, Google=4, Custom=1
|
||||||
|
# TTS_BATCH_SIZE=2
|
||||||
|
|
||||||
|
# VOYAGE AI
|
||||||
|
# VOYAGE_API_KEY=
|
||||||
|
|
||||||
|
# OPENAI COMPATIBLE ENDPOINTS
|
||||||
|
# Generic configuration (applies to all modalities: language, embedding, STT, TTS)
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL=http://localhost:1234/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY=
|
||||||
|
|
||||||
|
# Mode-specific configuration (overrides generic if set)
|
||||||
|
# Use these when you want different endpoints for different capabilities
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_LLM=http://localhost:1234/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_LLM=
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_EMBEDDING=http://localhost:8080/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_EMBEDDING=
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_STT=http://localhost:9000/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_STT=
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_TTS=http://localhost:9000/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_TTS=
|
||||||
|
|
||||||
|
# AZURE OPENAI
|
||||||
|
# Generic configuration (applies to all modalities: language, embedding, STT, TTS)
|
||||||
|
# AZURE_OPENAI_API_KEY=
|
||||||
|
# AZURE_OPENAI_ENDPOINT=
|
||||||
|
# AZURE_OPENAI_API_VERSION=2024-12-01-preview
|
||||||
|
|
||||||
|
# Mode-specific configuration (overrides generic if set)
|
||||||
|
# Use these when you want different deployments for different AI capabilities
|
||||||
|
# AZURE_OPENAI_API_KEY_LLM=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_LLM=
|
||||||
|
# AZURE_OPENAI_API_VERSION_LLM=
|
||||||
|
|
||||||
|
# AZURE_OPENAI_API_KEY_EMBEDDING=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_EMBEDDING=
|
||||||
|
# AZURE_OPENAI_API_VERSION_EMBEDDING=
|
||||||
|
|
||||||
|
# AZURE_OPENAI_API_KEY_STT=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_STT=
|
||||||
|
# AZURE_OPENAI_API_VERSION_STT=
|
||||||
|
|
||||||
|
# AZURE_OPENAI_API_KEY_TTS=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_TTS=
|
||||||
|
# AZURE_OPENAI_API_VERSION_TTS=
|
||||||
|
|
||||||
|
# USE THIS IF YOU WANT TO DEBUG THE APP ON LANGSMITH
|
||||||
|
# LANGCHAIN_TRACING_V2=true
|
||||||
|
# LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
|
||||||
|
# LANGCHAIN_API_KEY=
|
||||||
|
# LANGCHAIN_PROJECT="Open Notebook"
|
||||||
|
|
||||||
|
# CONNECTION DETAILS FOR YOUR SURREAL DB
|
||||||
|
# New format (preferred) - WebSocket URL
|
||||||
|
SURREAL_URL="ws://surrealdb/rpc:8000"
|
||||||
|
SURREAL_USER="root"
|
||||||
|
SURREAL_PASSWORD="root"
|
||||||
|
SURREAL_NAMESPACE="open_notebook"
|
||||||
|
SURREAL_DATABASE="staging"
|
||||||
|
|
||||||
|
# RETRY CONFIGURATION (surreal-commands v1.2.0+)
|
||||||
|
# Global defaults for all background commands unless explicitly overridden at command level
|
||||||
|
# These settings help commands automatically recover from transient failures like:
|
||||||
|
# - Database transaction conflicts during concurrent operations
|
||||||
|
# - Network timeouts when calling external APIs
|
||||||
|
# - Rate limits from LLM/embedding providers
|
||||||
|
# - Temporary resource unavailability
|
||||||
|
|
||||||
|
# Enable/disable retry globally (default: true)
|
||||||
|
# Set to false to disable retries for all commands (useful for debugging)
|
||||||
|
SURREAL_COMMANDS_RETRY_ENABLED=true
|
||||||
|
|
||||||
|
# Maximum retry attempts before giving up (default: 3)
|
||||||
|
# Database operations use 5 attempts (defined per-command)
|
||||||
|
# API calls use 3 attempts (defined per-command)
|
||||||
|
SURREAL_COMMANDS_RETRY_MAX_ATTEMPTS=3
|
||||||
|
|
||||||
|
# Wait strategy between retry attempts (default: exponential_jitter)
|
||||||
|
# Options: exponential_jitter, exponential, fixed, random
|
||||||
|
# - exponential_jitter: Recommended - prevents thundering herd during DB conflicts
|
||||||
|
# - exponential: Good for API rate limits (predictable backoff)
|
||||||
|
# - fixed: Use for quick recovery scenarios
|
||||||
|
# - random: Use when you want unpredictable retry timing
|
||||||
|
SURREAL_COMMANDS_RETRY_WAIT_STRATEGY=exponential_jitter
|
||||||
|
|
||||||
|
# Minimum wait time between retries in seconds (default: 1)
|
||||||
|
# Database conflicts: 1 second (fast retry for transient issues)
|
||||||
|
# API rate limits: 5 seconds (wait for quota reset)
|
||||||
|
SURREAL_COMMANDS_RETRY_WAIT_MIN=1
|
||||||
|
|
||||||
|
# Maximum wait time between retries in seconds (default: 30)
|
||||||
|
# Database conflicts: 30 seconds maximum
|
||||||
|
# API rate limits: 120 seconds maximum (defined per-command)
|
||||||
|
# Total retry time won't exceed max_attempts * wait_max
|
||||||
|
SURREAL_COMMANDS_RETRY_WAIT_MAX=30
|
||||||
|
|
||||||
|
# WORKER CONCURRENCY
|
||||||
|
# Maximum number of concurrent tasks in the worker pool (default: 5)
|
||||||
|
# This affects the likelihood of database transaction conflicts during batch operations
|
||||||
|
#
|
||||||
|
# Tuning guidelines based on deployment size:
|
||||||
|
# - Resource-constrained (low CPU/memory): 1-2 workers
|
||||||
|
# Reduces conflicts and resource usage, but slower processing
|
||||||
|
#
|
||||||
|
# - Normal deployment (balanced): 5 workers (RECOMMENDED)
|
||||||
|
# Good balance between throughput and conflict rate
|
||||||
|
# Retry logic handles occasional conflicts gracefully
|
||||||
|
#
|
||||||
|
# - Large instances (high CPU/memory): 10-20 workers
|
||||||
|
# Higher throughput but more frequent DB conflicts
|
||||||
|
# Relies heavily on retry logic with jittered backoff
|
||||||
|
#
|
||||||
|
# Note: Higher concurrency increases vectorization speed but also increases
|
||||||
|
# SurrealDB transaction conflicts. The retry logic with exponential-jitter
|
||||||
|
# backoff ensures operations complete successfully even at high concurrency.
|
||||||
|
SURREAL_COMMANDS_MAX_TASKS=5
|
||||||
|
|
||||||
|
# OPEN_NOTEBOOK_PASSWORD=
|
||||||
|
|
||||||
|
# FIRECRAWL - Get a key at https://firecrawl.dev/
|
||||||
|
FIRECRAWL_API_KEY=
|
||||||
|
|
||||||
|
# JINA - Get a key at https://jina.ai/
|
||||||
|
JINA_API_KEY=
|
||||||
@@ -0,0 +1,124 @@
|
|||||||
|
# Open Notebook
|
||||||
|
|
||||||
|
一个私有的、多模型的、100% 本地的、功能完整的 Google Notebook LM 替代方案
|
||||||
|
|
||||||
|
在人工智能主导的世界中,拥有思考🧠和获取新知识💡的能力,不应该成为少数人的特权,也不应该被限制在单一提供商。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
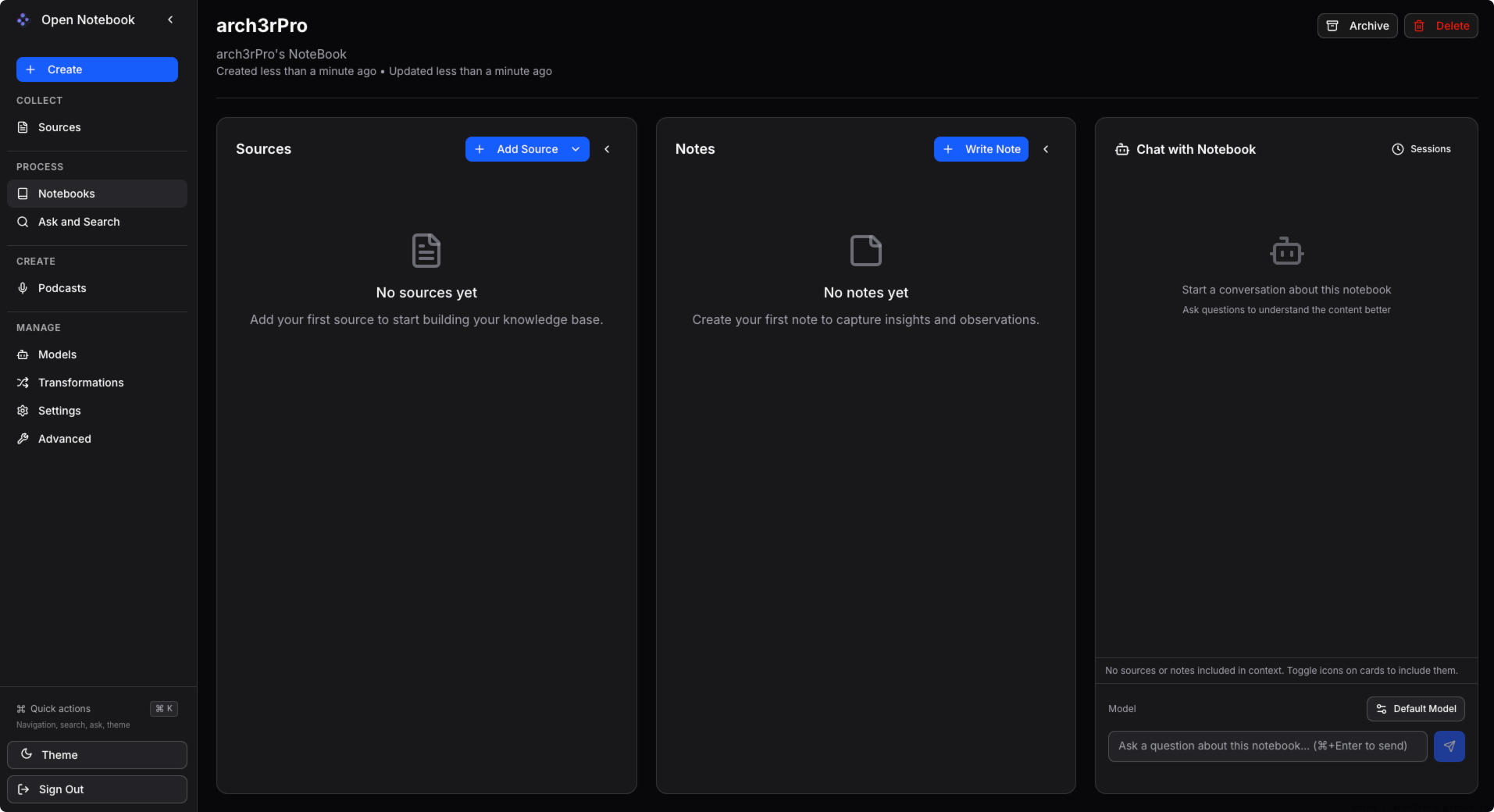
|
||||||
|
|
||||||
|
**Open Notebook 赋能您:**
|
||||||
|
- 🔒 **控制您的数据** - 保持您的研究私密和安全
|
||||||
|
- 🤖 **选择您的AI模型** - 支持16+个提供商,包括OpenAI、Anthropic、Ollama、LM Studio等
|
||||||
|
- 📚 **组织多模态内容** - PDF、视频、音频、网页等
|
||||||
|
- 🎙️ **生成专业播客** - 高级多说话人播客生成
|
||||||
|
- 🔍 **智能搜索** - 对所有内容进行全文和向量搜索
|
||||||
|
- 💬 **上下文聊天** - AI对话由您的研究驱动
|
||||||
|
|
||||||
|
在 [https://www.open-notebook.ai](https://www.open-notebook.ai) 了解我们项目的更多信息
|
||||||
|
|
||||||
|
## 🆚 Open Notebook vs Google Notebook LM
|
||||||
|
|
||||||
|
| 功能 | Open Notebook | Google Notebook LM | 优势 |
|
||||||
|
|---------|---------------|--------------------|-----------|
|
||||||
|
| **隐私和控制** | 自托管,您的数据 | 仅限谷歌云 | 完全的数据主权 |
|
||||||
|
| **AI提供商选择** | 16+提供商(OpenAI、Anthropic、Ollama、LM Studio等) | 仅谷歌模型 | 灵活性和成本优化 |
|
||||||
|
| **播客说话人** | 1-4个说话人,支持自定义配置 | 仅2个说话人 | 极致的灵活性 |
|
||||||
|
| **上下文控制** | 3个细粒度级别 | 全有或全无 | 隐私和性能调优 |
|
||||||
|
| **内容转换** | 自定义和内置 | 有限选项 | 无限的处理能力 |
|
||||||
|
| **API访问** | 完整REST API | 无API | 完整自动化 |
|
||||||
|
| **部署** | Docker、云端或本地 | 仅谷歌托管 | 随处部署 |
|
||||||
|
| **引用** | 带源的完整引用 | 基本引用 | 研究完整性 |
|
||||||
|
| **定制** | 开源,完全可定制 | 封闭系统 | 无限扩展性 |
|
||||||
|
| **成本** | 仅支付AI使用费 | 每月订阅+使用量 | 透明可控 |
|
||||||
|
|
||||||
|
**为什么选择Open Notebook?**
|
||||||
|
- 🔒 **隐私优先**: 您的敏感研究保持完全私密
|
||||||
|
- 💰 **成本控制**: 选择更便宜的AI提供商或使用Ollama本地运行
|
||||||
|
- 🎙️ **更好的播客**: 完整脚本控制和多说话人灵活性,优于有限的2说话人深度分析格式
|
||||||
|
- 🔧 **无限定制**: 根据需要修改、扩展和集成
|
||||||
|
- 🌐 **无供应商锁定**: 切换提供商、随处部署、拥有您的数据
|
||||||
|
|
||||||
|
### Open Notebook 工作原理
|
||||||
|
|
||||||
|
```
|
||||||
|
┌─────────────────────────────────────────────────────────┐
|
||||||
|
│ 您的浏览器 │
|
||||||
|
│ 访问地址: http://您的服务器IP:8502 │
|
||||||
|
└────────────────┬────────────────────────────────────────┘
|
||||||
|
│
|
||||||
|
▼
|
||||||
|
┌───────────────┐
|
||||||
|
│ 端口 8502 │ ← Next.js 前端(您看到的界面)
|
||||||
|
│ 前端 │ 同时在内部代理API请求!
|
||||||
|
└───────┬───────┘
|
||||||
|
│ 代理 /api/* 请求 ↓
|
||||||
|
▼
|
||||||
|
┌───────────────┐
|
||||||
|
│ 端口 5055 │ ← FastAPI 后端(处理请求)
|
||||||
|
│ API │
|
||||||
|
└───────┬───────┘
|
||||||
|
│
|
||||||
|
▼
|
||||||
|
┌───────────────┐
|
||||||
|
│ SurrealDB │ ← 数据库(内部,自动配置)
|
||||||
|
│ (端口 8000) │
|
||||||
|
└───────────────┘
|
||||||
|
```
|
||||||
|
|
||||||
|
**关键要点:**
|
||||||
|
- **v1.1+**: Next.js自动代理 `/api/*` 请求到后端,简化反向代理设置
|
||||||
|
- 您的浏览器从端口8502加载前端
|
||||||
|
- 前端需要知道在哪里找到API - 远程访问时,设置:`API_URL=http://您的服务器IP:5055`
|
||||||
|
- **使用反向代理?** 现在您只需要代理到端口8502!请参阅[反向代理指南](docs/deployment/reverse-proxy.md)
|
||||||
|
|
||||||
|
## 提供商支持矩阵
|
||||||
|
|
||||||
|
感谢 [Esperanto](https://github.com/lfnovo/esperanto) 库,我们开箱即用地支持这些提供商!
|
||||||
|
|
||||||
|
| 提供商 | LLM支持 | 嵌入支持 | 语音转文本 | 文本转语音 |
|
||||||
|
|--------------|-------------|------------------|----------------|----------------|
|
||||||
|
| OpenAI | ✅ | ✅ | ✅ | ✅ |
|
||||||
|
| Anthropic | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| Groq | ✅ | ❌ | ✅ | ❌ |
|
||||||
|
| Google (GenAI) | ✅ | ✅ | ❌ | ✅ |
|
||||||
|
| Vertex AI | ✅ | ✅ | ❌ | ✅ |
|
||||||
|
| Ollama | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| Perplexity | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| ElevenLabs | ❌ | ❌ | ✅ | ✅ |
|
||||||
|
| Azure OpenAI | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| Mistral | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| DeepSeek | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| Voyage | ❌ | ✅ | ❌ | ❌ |
|
||||||
|
| xAI | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| OpenRouter | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| OpenAI 兼容* | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
|
||||||
|
*支持LM Studio和任何OpenAI兼容端点
|
||||||
|
|
||||||
|
## ✨ 主要功能
|
||||||
|
|
||||||
|
### 核心能力
|
||||||
|
- **🔒 隐私优先**: 您的数据保持在您的控制下 - 无云依赖
|
||||||
|
- **🎯 多笔记本组织**: 无缝管理多个研究项目
|
||||||
|
- **📚 通用内容支持**: PDF、视频、音频、网页、Office文档等
|
||||||
|
- **🤖 多模型AI支持**: 16+提供商,包括OpenAI、Anthropic、Ollama、Google、LM Studio等
|
||||||
|
- **🎙️ 专业播客生成**: 带有剧集配置的高级多说话人播客
|
||||||
|
- **🔍 智能搜索**: 对所有内容进行全文和向量搜索
|
||||||
|
- **💬 上下文感知聊天**: AI对话由您的研究材料驱动
|
||||||
|
- **📝 AI辅助笔记**: 生成洞察或手动写笔记
|
||||||
|
|
||||||
|
### 高级功能
|
||||||
|
- **⚡ 推理模型支持**: 对DeepSeek-R1和Qwen3等思考模型的完整支持
|
||||||
|
- **🔧 内容转换**: 强大的可自定义操作,用于总结和提取洞察
|
||||||
|
- **🌐 完整REST API**: 自定义集成的完整程序化访问 [](http://localhost:5055/docs)
|
||||||
|
- **🔐 可选密码保护**: 通过身份验证保护公共部署
|
||||||
|
- **📊 细粒度上下文控制**: 选择与AI模型分享的确切内容
|
||||||
|
- **📎 引用**: 获取带有正确源引用的答案
|
||||||
|
|
||||||
|
### 三栏界面
|
||||||
|
1. **源**: 管理所有研究材料
|
||||||
|
2. **笔记**: 创建手动或AI生成的笔记
|
||||||
|
3. **聊天**: 使用您的内容作为上下文与AI对话
|
||||||
|
|
||||||
@@ -0,0 +1,129 @@
|
|||||||
|
# Open Notebook
|
||||||
|
|
||||||
|
A private, multi-model, 100% local, full-featured alternative to Notebook LM
|
||||||
|
|
||||||
|
In a world dominated by Artificial Intelligence, having the ability to think 🧠 and acquire new knowledge 💡, is a skill that should not be a privilege for a few, nor restricted to a single provider.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
**Open Notebook empowers you to:**
|
||||||
|
- 🔒 **Control your data** - Keep your research private and secure
|
||||||
|
- 🤖 **Choose your AI models** - Support for 16+ providers including OpenAI, Anthropic, Ollama, LM Studio, and more
|
||||||
|
- 📚 **Organize multi-modal content** - PDFs, videos, audio, web pages, and more
|
||||||
|
- 🎙️ **Generate professional podcasts** - Advanced multi-speaker podcast generation
|
||||||
|
- 🔍 **Search intelligently** - Full-text and vector search across all your content
|
||||||
|
- 💬 **Chat with context** - AI conversations powered by your research
|
||||||
|
|
||||||
|
Learn more about our project at [https://www.open-notebook.ai](https://www.open-notebook.ai)
|
||||||
|
|
||||||
|
## 🆚 Open Notebook vs Google Notebook LM
|
||||||
|
|
||||||
|
| Feature | Open Notebook | Google Notebook LM | Advantage |
|
||||||
|
|---------|---------------|--------------------|-----------|
|
||||||
|
| **Privacy & Control** | Self-hosted, your data | Google cloud only | Complete data sovereignty |
|
||||||
|
| **AI Provider Choice** | 16+ providers (OpenAI, Anthropic, Ollama, LM Studio, etc.) | Google models only | Flexibility and cost optimization |
|
||||||
|
| **Podcast Speakers** | 1-4 speakers with custom profiles | 2 speakers only | Extreme flexibility |
|
||||||
|
| **Context Control** | 3 granular levels | All-or-nothing | Privacy and performance tuning |
|
||||||
|
| **Content Transformations** | Custom and built-in | Limited options | Unlimited processing power |
|
||||||
|
| **API Access** | Full REST API | No API | Complete automation |
|
||||||
|
| **Deployment** | Docker, cloud, or local | Google hosted only | Deploy anywhere |
|
||||||
|
| **Citations** | Comprehensive with sources | Basic references | Research integrity |
|
||||||
|
| **Customization** | Open source, fully customizable | Closed system | Unlimited extensibility |
|
||||||
|
| **Cost** | Pay only for AI usage | Monthly subscription + usage | Transparent and controllable |
|
||||||
|
|
||||||
|
**Why Choose Open Notebook?**
|
||||||
|
- 🔒 **Privacy First**: Your sensitive research stays completely private
|
||||||
|
- 💰 **Cost Control**: Choose cheaper AI providers or run locally with Ollama
|
||||||
|
- 🎙️ **Better Podcasts**: Full script control and multi-speaker flexibility vs limited 2-speaker deep-dive format
|
||||||
|
- 🔧 **Unlimited Customization**: Modify, extend, and integrate as needed
|
||||||
|
- 🌐 **No Vendor Lock-in**: Switch providers, deploy anywhere, own your data
|
||||||
|
|
||||||
|
|
||||||
|
### How Open Notebook Works
|
||||||
|
|
||||||
|
```
|
||||||
|
┌─────────────────────────────────────────────────────────┐
|
||||||
|
│ Your Browser │
|
||||||
|
│ Access: http://your-server-ip:8502 │
|
||||||
|
└────────────────┬────────────────────────────────────────┘
|
||||||
|
│
|
||||||
|
▼
|
||||||
|
┌───────────────┐
|
||||||
|
│ Port 8502 │ ← Next.js Frontend (what you see)
|
||||||
|
│ Frontend │ Also proxies API requests internally!
|
||||||
|
└───────┬───────┘
|
||||||
|
│ proxies /api/* requests ↓
|
||||||
|
▼
|
||||||
|
┌───────────────┐
|
||||||
|
│ Port 5055 │ ← FastAPI Backend (handles requests)
|
||||||
|
│ API │
|
||||||
|
└───────┬───────┘
|
||||||
|
│
|
||||||
|
▼
|
||||||
|
┌───────────────┐
|
||||||
|
│ SurrealDB │ ← Database (internal, auto-configured)
|
||||||
|
│ (Port 8000) │
|
||||||
|
└───────────────┘
|
||||||
|
```
|
||||||
|
|
||||||
|
**Key Points:**
|
||||||
|
- **v1.1+**: Next.js automatically proxies `/api/*` requests to the backend, simplifying reverse proxy setup
|
||||||
|
- Your browser loads the frontend from port 8502
|
||||||
|
- The frontend needs to know where to find the API - when accessing remotely, set: `API_URL=http://your-server-ip:5055`
|
||||||
|
- **Behind reverse proxy?** You only need to proxy to port 8502 now! See [Reverse Proxy Guide](docs/deployment/reverse-proxy.md)
|
||||||
|
|
||||||
|
## Provider Support Matrix
|
||||||
|
|
||||||
|
Thanks to the [Esperanto](https://github.com/lfnovo/esperanto) library, we support this providers out of the box!
|
||||||
|
|
||||||
|
| Provider | LLM Support | Embedding Support | Speech-to-Text | Text-to-Speech |
|
||||||
|
|--------------|-------------|------------------|----------------|----------------|
|
||||||
|
| OpenAI | ✅ | ✅ | ✅ | ✅ |
|
||||||
|
| Anthropic | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| Groq | ✅ | ❌ | ✅ | ❌ |
|
||||||
|
| Google (GenAI) | ✅ | ✅ | ❌ | ✅ |
|
||||||
|
| Vertex AI | ✅ | ✅ | ❌ | ✅ |
|
||||||
|
| Ollama | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| Perplexity | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| ElevenLabs | ❌ | ❌ | ✅ | ✅ |
|
||||||
|
| Azure OpenAI | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| Mistral | ✅ | ✅ | ❌ | ❌ |
|
||||||
|
| DeepSeek | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| Voyage | ❌ | ✅ | ❌ | ❌ |
|
||||||
|
| xAI | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| OpenRouter | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
| OpenAI Compatible* | ✅ | ❌ | ❌ | ❌ |
|
||||||
|
|
||||||
|
*Supports LM Studio and any OpenAI-compatible endpoint
|
||||||
|
|
||||||
|
## ✨ Key Features
|
||||||
|
|
||||||
|
### Core Capabilities
|
||||||
|
- **🔒 Privacy-First**: Your data stays under your control - no cloud dependencies
|
||||||
|
- **🎯 Multi-Notebook Organization**: Manage multiple research projects seamlessly
|
||||||
|
- **📚 Universal Content Support**: PDFs, videos, audio, web pages, Office docs, and more
|
||||||
|
- **🤖 Multi-Model AI Support**: 16+ providers including OpenAI, Anthropic, Ollama, Google, LM Studio, and more
|
||||||
|
- **🎙️ Professional Podcast Generation**: Advanced multi-speaker podcasts with Episode Profiles
|
||||||
|
- **🔍 Intelligent Search**: Full-text and vector search across all your content
|
||||||
|
- **💬 Context-Aware Chat**: AI conversations powered by your research materials
|
||||||
|
- **📝 AI-Assisted Notes**: Generate insights or write notes manually
|
||||||
|
|
||||||
|
### Advanced Features
|
||||||
|
- **⚡ Reasoning Model Support**: Full support for thinking models like DeepSeek-R1 and Qwen3
|
||||||
|
- **🔧 Content Transformations**: Powerful customizable actions to summarize and extract insights
|
||||||
|
- **🌐 Comprehensive REST API**: Full programmatic access for custom integrations [](http://localhost:5055/docs)
|
||||||
|
- **🔐 Optional Password Protection**: Secure public deployments with authentication
|
||||||
|
- **📊 Fine-Grained Context Control**: Choose exactly what to share with AI models
|
||||||
|
- **📎 Citations**: Get answers with proper source citations
|
||||||
|
|
||||||
|
### Three-Column Interface
|
||||||
|
1. **Sources**: Manage all your research materials
|
||||||
|
2. **Notes**: Create manual or AI-generated notes
|
||||||
|
3. **Chat**: Converse with AI using your content as context
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@@ -0,0 +1,26 @@
|
|||||||
|
name: Open Notebook
|
||||||
|
tags:
|
||||||
|
- 实用工具
|
||||||
|
- Web 服务器
|
||||||
|
title: 一个开源的、注重隐私的 Google Notebook LM 替代方案!
|
||||||
|
description:
|
||||||
|
en: An open source, privacy-focused alternative to Google's Notebook LM!
|
||||||
|
zh: 一个开源的、注重隐私的 Google Notebook LM 替代方案!
|
||||||
|
additionalProperties:
|
||||||
|
key: open-notebook
|
||||||
|
name: Open Notebook
|
||||||
|
tags:
|
||||||
|
- Tool
|
||||||
|
- Server
|
||||||
|
shortDescZh: 一个开源的、注重隐私的 Google Notebook LM 替代方案!
|
||||||
|
shortDescEn: An open source, privacy-focused alternative to Google's Notebook LM!
|
||||||
|
type: website
|
||||||
|
crossVersionUpdate: true
|
||||||
|
limit: 0
|
||||||
|
website: https://www.open-notebook.ai
|
||||||
|
github: https://github.com/lfnovo/open-notebook
|
||||||
|
document: https://www.open-notebook.ai/get-started.html
|
||||||
|
memoryRequired: 2048
|
||||||
|
architectures:
|
||||||
|
- amd64
|
||||||
|
- arm64
|
||||||
@@ -0,0 +1,26 @@
|
|||||||
|
additionalProperties:
|
||||||
|
formFields:
|
||||||
|
- default: "8502"
|
||||||
|
envKey: PANEL_APP_PORT_HTTP
|
||||||
|
required: true
|
||||||
|
type: number
|
||||||
|
labelEn: Port
|
||||||
|
labelZh: 端口
|
||||||
|
edit: true
|
||||||
|
rule: paramPort
|
||||||
|
- default: "5055"
|
||||||
|
envKey: PANEL_APP_PORT_API
|
||||||
|
required: true
|
||||||
|
type: number
|
||||||
|
labelEn: API Port
|
||||||
|
labelZh: API端口
|
||||||
|
edit: true
|
||||||
|
rule: paramPort
|
||||||
|
- default: "8000"
|
||||||
|
envKey: PANEL_APP_PORT_DB
|
||||||
|
required: true
|
||||||
|
type: number
|
||||||
|
labelEn: Database Port
|
||||||
|
labelZh: 数据库端口
|
||||||
|
edit: true
|
||||||
|
rule: paramPort
|
||||||
@@ -0,0 +1,38 @@
|
|||||||
|
services:
|
||||||
|
open_notebook:
|
||||||
|
image: lfnovo/open_notebook:v1-latest
|
||||||
|
ports:
|
||||||
|
- ${PANEL_APP_PORT_HTTP}:8502
|
||||||
|
- ${PANEL_APP_PORT_API}:5055
|
||||||
|
env_file:
|
||||||
|
- ./docker.env
|
||||||
|
depends_on:
|
||||||
|
- surrealdb
|
||||||
|
volumes:
|
||||||
|
- ./notebook_data:/app/data
|
||||||
|
restart: always
|
||||||
|
container_name: ${CONTAINER_NAME}
|
||||||
|
networks:
|
||||||
|
- 1panel-network
|
||||||
|
labels:
|
||||||
|
createdBy: Apps
|
||||||
|
surrealdb:
|
||||||
|
image: surrealdb/surrealdb:v2
|
||||||
|
volumes:
|
||||||
|
- ./surreal_data:/mydata
|
||||||
|
environment:
|
||||||
|
- SURREAL_EXPERIMENTAL_GRAPHQL=true
|
||||||
|
ports:
|
||||||
|
- ${PANEL_APP_PORT_DB}:8000
|
||||||
|
command: start --log info --user root --pass root rocksdb:/mydata/mydatabase.db
|
||||||
|
pull_policy: always
|
||||||
|
user: root
|
||||||
|
restart: always
|
||||||
|
container_name: ${CONTAINER_NAME}-surrealdb
|
||||||
|
networks:
|
||||||
|
- 1panel-network
|
||||||
|
labels:
|
||||||
|
createdBy: Apps
|
||||||
|
networks:
|
||||||
|
1panel-network:
|
||||||
|
external: true
|
||||||
@@ -0,0 +1,259 @@
|
|||||||
|
|
||||||
|
# API CONFIGURATION
|
||||||
|
# URL where the API can be accessed by the browser
|
||||||
|
# This setting allows the frontend to connect to the API at runtime (no rebuild needed!)
|
||||||
|
#
|
||||||
|
# IMPORTANT: Do NOT include /api at the end - it will be added automatically!
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Docker on localhost: http://localhost:5055 (default, works for most cases)
|
||||||
|
# - Docker on LAN/remote server: http://192.168.1.100:5055 or http://your-server-ip:5055
|
||||||
|
# - Behind reverse proxy with custom domain: https://your-domain.com
|
||||||
|
# - Behind reverse proxy with subdomain: https://api.your-domain.com
|
||||||
|
#
|
||||||
|
# Examples for reverse proxy users:
|
||||||
|
# - API_URL=https://notebook.example.com (frontend will call https://notebook.example.com/api/*)
|
||||||
|
# - API_URL=https://api.example.com (frontend will call https://api.example.com/api/*)
|
||||||
|
#
|
||||||
|
# Note: If not set, the system will auto-detect based on the incoming request.
|
||||||
|
# Only set this if you need to override the auto-detection (e.g., reverse proxy scenarios).
|
||||||
|
API_URL=http://localhost:5055
|
||||||
|
|
||||||
|
# INTERNAL API URL (Server-Side)
|
||||||
|
# URL where Next.js server-side should proxy API requests (via rewrites)
|
||||||
|
# This is DIFFERENT from API_URL which is used by the browser client
|
||||||
|
#
|
||||||
|
# INTERNAL_API_URL is used by Next.js rewrites to forward /api/* requests to the FastAPI backend
|
||||||
|
# API_URL is used by the browser to know where to make API calls
|
||||||
|
#
|
||||||
|
# Default: http://localhost:5055 (single-container deployment - both services on same host)
|
||||||
|
# Override for multi-container: INTERNAL_API_URL=http://api-service:5055
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Single container (default): Don't set - defaults to http://localhost:5055
|
||||||
|
# - Multi-container Docker Compose: INTERNAL_API_URL=http://api:5055 (use service name)
|
||||||
|
# - Kubernetes/advanced networking: INTERNAL_API_URL=http://api-service.namespace.svc.cluster.local:5055
|
||||||
|
#
|
||||||
|
# Why two variables?
|
||||||
|
# - API_URL: External/public URL that browsers use (can be https://your-domain.com)
|
||||||
|
# - INTERNAL_API_URL: Internal container networking URL (usually http://localhost:5055 or service name)
|
||||||
|
#
|
||||||
|
# INTERNAL_API_URL=http://localhost:5055
|
||||||
|
|
||||||
|
# API CLIENT TIMEOUT (in seconds)
|
||||||
|
# Controls how long the frontend/Streamlit UI waits for API responses
|
||||||
|
# Increase this if you're using slow AI providers or hardware (Ollama on CPU, remote LM Studio, etc.)
|
||||||
|
# Default: 300 seconds (5 minutes) - sufficient for most transformation/insight operations
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Fast cloud APIs (OpenAI, Anthropic): 300 seconds is more than enough
|
||||||
|
# - Local Ollama on GPU: 300 seconds should work fine
|
||||||
|
# - Local Ollama on CPU: Consider 600 seconds (10 minutes) or more
|
||||||
|
# - Remote LM Studio over slow network: Consider 900 seconds (15 minutes)
|
||||||
|
# - Very large documents: May need 900+ seconds
|
||||||
|
#
|
||||||
|
# API_CLIENT_TIMEOUT=300
|
||||||
|
|
||||||
|
# ESPERANTO LLM TIMEOUT (in seconds)
|
||||||
|
# Controls the timeout for AI model API calls at the Esperanto library level
|
||||||
|
# This is separate from API_CLIENT_TIMEOUT and applies to the actual LLM provider requests
|
||||||
|
# Only increase this if you're experiencing timeouts during model inference itself
|
||||||
|
# Default: 60 seconds (built into Esperanto)
|
||||||
|
#
|
||||||
|
# Important: This should generally be LOWER than API_CLIENT_TIMEOUT to allow proper error handling
|
||||||
|
#
|
||||||
|
# Common scenarios:
|
||||||
|
# - Fast cloud APIs (OpenAI, Anthropic, Groq): 60 seconds is sufficient
|
||||||
|
# - Local Ollama with small models: 120-180 seconds may help
|
||||||
|
# - Local Ollama with large models on CPU: 300+ seconds
|
||||||
|
# - Remote or self-hosted LLMs: 180-300 seconds depending on hardware
|
||||||
|
#
|
||||||
|
# Note: If transformations complete but you see timeout errors, increase API_CLIENT_TIMEOUT first.
|
||||||
|
# Only increase ESPERANTO_LLM_TIMEOUT if the model itself is timing out during inference.
|
||||||
|
#
|
||||||
|
# ESPERANTO_LLM_TIMEOUT=60
|
||||||
|
|
||||||
|
# SSL VERIFICATION CONFIGURATION
|
||||||
|
# Configure SSL certificate verification for local AI providers (Ollama, LM Studio, etc.)
|
||||||
|
# behind reverse proxies with self-signed certificates
|
||||||
|
#
|
||||||
|
# Option 1: Custom CA Bundle (recommended for self-signed certs)
|
||||||
|
# Point to your CA certificate file to verify SSL while using custom certificates
|
||||||
|
# ESPERANTO_SSL_CA_BUNDLE=/path/to/your/ca-bundle.pem
|
||||||
|
#
|
||||||
|
# Option 2: Disable SSL Verification (development only)
|
||||||
|
# WARNING: Disabling SSL verification exposes you to man-in-the-middle attacks
|
||||||
|
# Only use in trusted development/testing environments
|
||||||
|
# ESPERANTO_SSL_VERIFY=false
|
||||||
|
|
||||||
|
# SECURITY
|
||||||
|
# Set this to protect your Open Notebook instance with a password (for public hosting)
|
||||||
|
# OPEN_NOTEBOOK_PASSWORD=
|
||||||
|
|
||||||
|
# OPENAI
|
||||||
|
# OPENAI_API_KEY=
|
||||||
|
|
||||||
|
|
||||||
|
# ANTHROPIC
|
||||||
|
# ANTHROPIC_API_KEY=
|
||||||
|
|
||||||
|
# GEMINI
|
||||||
|
# this is the best model for long context and podcast generation
|
||||||
|
# GOOGLE_API_KEY=
|
||||||
|
# GEMINI_API_BASE_URL= # Optional: Override default endpoint (for Vertex AI, proxies, etc.)
|
||||||
|
|
||||||
|
# VERTEXAI
|
||||||
|
# VERTEX_PROJECT=my-google-cloud-project-name
|
||||||
|
# GOOGLE_APPLICATION_CREDENTIALS=./google-credentials.json
|
||||||
|
# VERTEX_LOCATION=us-east5
|
||||||
|
|
||||||
|
# MISTRAL
|
||||||
|
# MISTRAL_API_KEY=
|
||||||
|
|
||||||
|
# DEEPSEEK
|
||||||
|
# DEEPSEEK_API_KEY=
|
||||||
|
|
||||||
|
# OLLAMA
|
||||||
|
# OLLAMA_API_BASE="http://10.20.30.20:11434"
|
||||||
|
|
||||||
|
# OPEN ROUTER
|
||||||
|
# OPENROUTER_BASE_URL="https://openrouter.ai/api/v1"
|
||||||
|
# OPENROUTER_API_KEY=
|
||||||
|
|
||||||
|
# GROQ
|
||||||
|
# GROQ_API_KEY=
|
||||||
|
|
||||||
|
# XAI
|
||||||
|
# XAI_API_KEY=
|
||||||
|
|
||||||
|
# ELEVENLABS
|
||||||
|
# Used only by the podcast feature
|
||||||
|
# ELEVENLABS_API_KEY=
|
||||||
|
|
||||||
|
# TTS BATCH SIZE
|
||||||
|
# Controls concurrent TTS requests for podcast generation (default: 5)
|
||||||
|
# Lower values reduce provider load but increase generation time
|
||||||
|
# Recommended: OpenAI=5, ElevenLabs=2, Google=4, Custom=1
|
||||||
|
# TTS_BATCH_SIZE=2
|
||||||
|
|
||||||
|
# VOYAGE AI
|
||||||
|
# VOYAGE_API_KEY=
|
||||||
|
|
||||||
|
# OPENAI COMPATIBLE ENDPOINTS
|
||||||
|
# Generic configuration (applies to all modalities: language, embedding, STT, TTS)
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL=http://localhost:1234/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY=
|
||||||
|
|
||||||
|
# Mode-specific configuration (overrides generic if set)
|
||||||
|
# Use these when you want different endpoints for different capabilities
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_LLM=http://localhost:1234/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_LLM=
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_EMBEDDING=http://localhost:8080/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_EMBEDDING=
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_STT=http://localhost:9000/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_STT=
|
||||||
|
# OPENAI_COMPATIBLE_BASE_URL_TTS=http://localhost:9000/v1
|
||||||
|
# OPENAI_COMPATIBLE_API_KEY_TTS=
|
||||||
|
|
||||||
|
# AZURE OPENAI
|
||||||
|
# Generic configuration (applies to all modalities: language, embedding, STT, TTS)
|
||||||
|
# AZURE_OPENAI_API_KEY=
|
||||||
|
# AZURE_OPENAI_ENDPOINT=
|
||||||
|
# AZURE_OPENAI_API_VERSION=2024-12-01-preview
|
||||||
|
|
||||||
|
# Mode-specific configuration (overrides generic if set)
|
||||||
|
# Use these when you want different deployments for different AI capabilities
|
||||||
|
# AZURE_OPENAI_API_KEY_LLM=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_LLM=
|
||||||
|
# AZURE_OPENAI_API_VERSION_LLM=
|
||||||
|
|
||||||
|
# AZURE_OPENAI_API_KEY_EMBEDDING=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_EMBEDDING=
|
||||||
|
# AZURE_OPENAI_API_VERSION_EMBEDDING=
|
||||||
|
|
||||||
|
# AZURE_OPENAI_API_KEY_STT=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_STT=
|
||||||
|
# AZURE_OPENAI_API_VERSION_STT=
|
||||||
|
|
||||||
|
# AZURE_OPENAI_API_KEY_TTS=
|
||||||
|
# AZURE_OPENAI_ENDPOINT_TTS=
|
||||||
|
# AZURE_OPENAI_API_VERSION_TTS=
|
||||||
|
|
||||||
|
# USE THIS IF YOU WANT TO DEBUG THE APP ON LANGSMITH
|
||||||
|
# LANGCHAIN_TRACING_V2=true
|
||||||
|
# LANGCHAIN_ENDPOINT="https://api.smith.langchain.com"
|
||||||
|
# LANGCHAIN_API_KEY=
|
||||||
|
# LANGCHAIN_PROJECT="Open Notebook"
|
||||||
|
|
||||||
|
# CONNECTION DETAILS FOR YOUR SURREAL DB
|
||||||
|
# New format (preferred) - WebSocket URL
|
||||||
|
SURREAL_URL="ws://surrealdb/rpc:8000"
|
||||||
|
SURREAL_USER="root"
|
||||||
|
SURREAL_PASSWORD="root"
|
||||||
|
SURREAL_NAMESPACE="open_notebook"
|
||||||
|
SURREAL_DATABASE="staging"
|
||||||
|
|
||||||
|
# RETRY CONFIGURATION (surreal-commands v1.2.0+)
|
||||||
|
# Global defaults for all background commands unless explicitly overridden at command level
|
||||||
|
# These settings help commands automatically recover from transient failures like:
|
||||||
|
# - Database transaction conflicts during concurrent operations
|
||||||
|
# - Network timeouts when calling external APIs
|
||||||
|
# - Rate limits from LLM/embedding providers
|
||||||
|
# - Temporary resource unavailability
|
||||||
|
|
||||||
|
# Enable/disable retry globally (default: true)
|
||||||
|
# Set to false to disable retries for all commands (useful for debugging)
|
||||||
|
SURREAL_COMMANDS_RETRY_ENABLED=true
|
||||||
|
|
||||||
|
# Maximum retry attempts before giving up (default: 3)
|
||||||
|
# Database operations use 5 attempts (defined per-command)
|
||||||
|
# API calls use 3 attempts (defined per-command)
|
||||||
|
SURREAL_COMMANDS_RETRY_MAX_ATTEMPTS=3
|
||||||
|
|
||||||
|
# Wait strategy between retry attempts (default: exponential_jitter)
|
||||||
|
# Options: exponential_jitter, exponential, fixed, random
|
||||||
|
# - exponential_jitter: Recommended - prevents thundering herd during DB conflicts
|
||||||
|
# - exponential: Good for API rate limits (predictable backoff)
|
||||||
|
# - fixed: Use for quick recovery scenarios
|
||||||
|
# - random: Use when you want unpredictable retry timing
|
||||||
|
SURREAL_COMMANDS_RETRY_WAIT_STRATEGY=exponential_jitter
|
||||||
|
|
||||||
|
# Minimum wait time between retries in seconds (default: 1)
|
||||||
|
# Database conflicts: 1 second (fast retry for transient issues)
|
||||||
|
# API rate limits: 5 seconds (wait for quota reset)
|
||||||
|
SURREAL_COMMANDS_RETRY_WAIT_MIN=1
|
||||||
|
|
||||||
|
# Maximum wait time between retries in seconds (default: 30)
|
||||||
|
# Database conflicts: 30 seconds maximum
|
||||||
|
# API rate limits: 120 seconds maximum (defined per-command)
|
||||||
|
# Total retry time won't exceed max_attempts * wait_max
|
||||||
|
SURREAL_COMMANDS_RETRY_WAIT_MAX=30
|
||||||
|
|
||||||
|
# WORKER CONCURRENCY
|
||||||
|
# Maximum number of concurrent tasks in the worker pool (default: 5)
|
||||||
|
# This affects the likelihood of database transaction conflicts during batch operations
|
||||||
|
#
|
||||||
|
# Tuning guidelines based on deployment size:
|
||||||
|
# - Resource-constrained (low CPU/memory): 1-2 workers
|
||||||
|
# Reduces conflicts and resource usage, but slower processing
|
||||||
|
#
|
||||||
|
# - Normal deployment (balanced): 5 workers (RECOMMENDED)
|
||||||
|
# Good balance between throughput and conflict rate
|
||||||
|
# Retry logic handles occasional conflicts gracefully
|
||||||
|
#
|
||||||
|
# - Large instances (high CPU/memory): 10-20 workers
|
||||||
|
# Higher throughput but more frequent DB conflicts
|
||||||
|
# Relies heavily on retry logic with jittered backoff
|
||||||
|
#
|
||||||
|
# Note: Higher concurrency increases vectorization speed but also increases
|
||||||
|
# SurrealDB transaction conflicts. The retry logic with exponential-jitter
|
||||||
|
# backoff ensures operations complete successfully even at high concurrency.
|
||||||
|
SURREAL_COMMANDS_MAX_TASKS=5
|
||||||
|
|
||||||
|
# OPEN_NOTEBOOK_PASSWORD=
|
||||||
|
|
||||||
|
# FIRECRAWL - Get a key at https://firecrawl.dev/
|
||||||
|
FIRECRAWL_API_KEY=
|
||||||
|
|
||||||
|
# JINA - Get a key at https://jina.ai/
|
||||||
|
JINA_API_KEY=
|
||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 47 KiB |
Reference in New Issue
Block a user